How We Built witn's Outcome Resolution Layer for Low Latency and Reliability
Explore the engineering of a low-latency, high-reliability outcome resolution layer for AI agent billing. Learn how we solved for correctness and scale.
The Core Conflict in AI Agent Billing
Billing for AI agents presents a unique engineering challenge. Unlike traditional SaaS where value is tied to a predictable seat license, an agent's value is generated through a non-deterministic series of actions and outcomes. This creates a fundamental conflict for the underlying infrastructure. The system must provide the strict, auditable correctness that billing demands. It must also deliver the high throughput and low latency that real-time agent interactions require. These two goals pull in opposite directions.
We built our outcome resolution layer to solve this conflict. This layer sits between an agent's raw event stream and the final invoice, interpreting complex event sequences to determine billable value. We made the case for why this layer exists in The Missing Layer in AI Agent Monetization. This post is about how we engineered it.
A simple approach, like a cron job that periodically scans a database, is guaranteed to fail. We knew from first principles that such a design collapses under real-world conditions. Its failure points are immediate and severe.
- It cannot handle out-of-order or late-arriving events common in distributed systems.
- It offers no clear path for handling reversals or cancellations during a settlement window.
- It lacks a verifiable audit trail, making it impossible to defend a charge to a customer.
- It does not scale to handle bursty, high-volume event streams from thousands of concurrent agents.
This problem's gravity makes a serious infrastructure investment unavoidable. There are no shortcuts to correctness when revenue is on the line.
Solving for Sub-10ms Ingestion Latency
The first requirement for our system was clear. Billing infrastructure must never become a performance bottleneck for the AI agents it serves. This meant accepting and acknowledging events in single-digit milliseconds. From the agent's perspective, sending a billing event had to be a fire-and-forget operation.
To achieve this, we completely decoupled event ingestion from processing. We chose Redpanda as our streaming backbone. When an event arrives at our API, we perform minimal validation, assign a deterministic ID and write it to a durable, ordered log in Redpanda. We then immediately return a success acknowledgment to the client. This keeps the agent's hot path clean and fast. All computationally expensive work, such as database writes, state evaluation and counter updates, happens asynchronously downstream.
Idempotency is critical in any distributed billing system. Network clients will inevitably retry requests. To prevent a single agent action from being billed multiple times, every event must be uniquely identifiable. Clients can supply an idempotency key for each event. Our ingestion pipeline derives a deterministic event ID from it and deduplicates any retried events, ensuring each action is processed only once.
Building this front door is a significant undertaking. Choosing, deploying, tuning and operating a high-throughput streaming platform like Redpanda requires specialized expertise. It represents the first major engineering investment where a simple in-house solution breaks down. This is not a weekend project. It is a core piece of production infrastructure that demands constant monitoring and operational readiness.
Managing Stateful Evaluation at Scale
After an event is safely ingested, the real work begins. The core of our resolution layer is a stateful stream processing engine. Each potential billable outcome, for every customer, for every agent, is its own state machine. These are not simple counters. They are evaluators that process AND/OR condition trees, time windows and event properties to determine if a billable condition has been met:
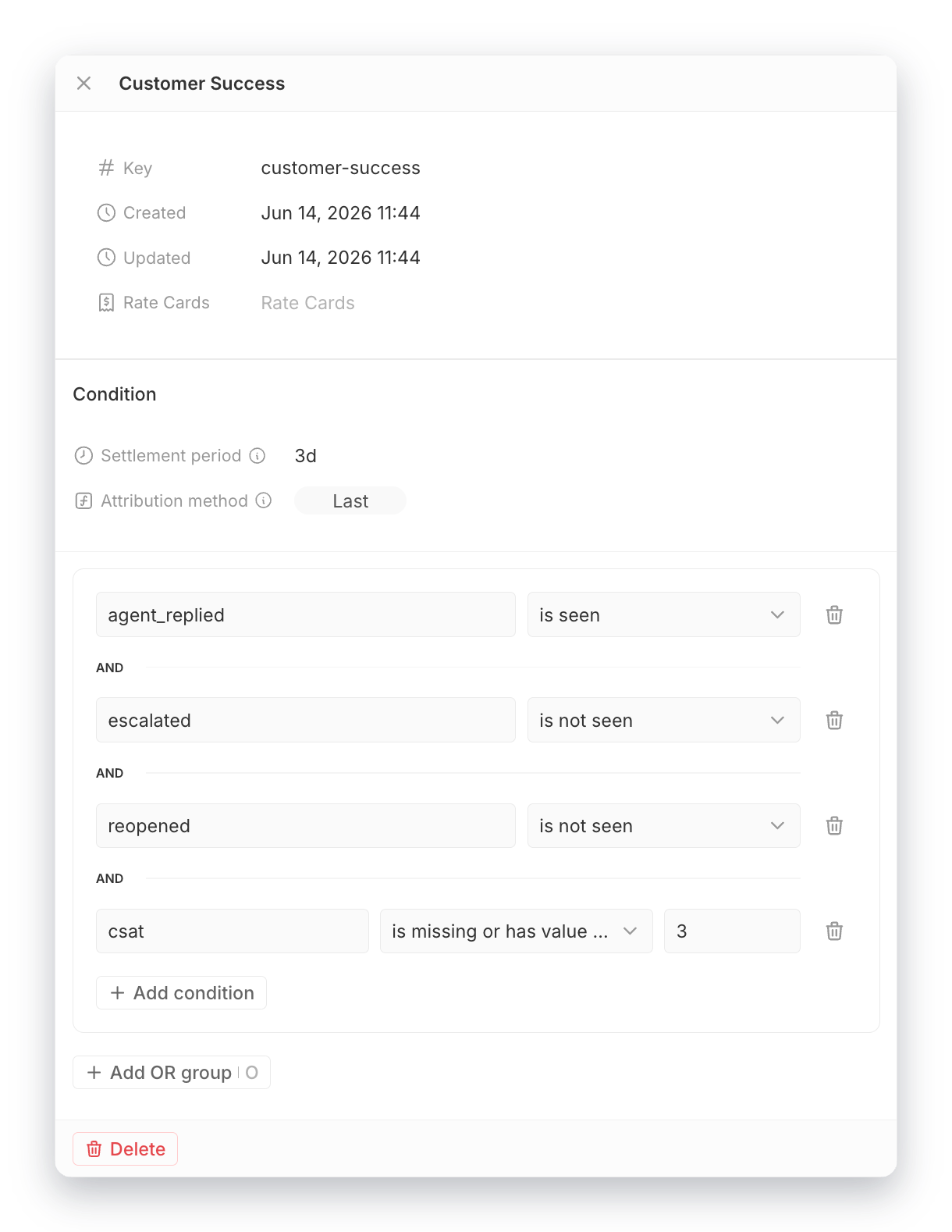
At any given moment, we are managing millions of these state machines concurrently. Running this evaluation against a traditional transactional database would create an immediate performance bottleneck. Instead, we use Dragonfly to hold the "hot" state for all active outcomes in memory. This design choice allows for microsecond-latency updates and condition checks. When an event is consumed from our Redpanda log, we fetch the relevant outcome's state from Dragonfly, evaluate the new event against its conditions and update the state, all without touching a disk.
We ensure data consistency in this high-velocity environment using optimistic concurrency control. Every state update uses a compare-and-swap operation on a state version number. This prevents race conditions between concurrent event processors without the overhead of expensive distributed locks. Our system is also designed to correctly handle late or out-of-order events. It re-evaluates an outcome's state based on immutable event timestamps, not the order in which events arrived in our system.
The operational burden here is immense. Managing millions of in-memory state machines and their associated settlement timers is a classic, hard distributed systems problem. This is not a feature you enable with a library. It is a core competency that took our team quarters to build correctly and now requires a permanent on-call rotation to maintain service levels. This is where the theoretical cost of building in-house becomes a real, ongoing operational expense.
Guaranteeing Exactly-Once Billing Effects
The most unforgiving requirement in any billing system is correctness. Specifically, this means guaranteeing exactly-once effects for any action that generates a charge. At-least-once delivery is a relatively solved problem in distributed systems. The truly difficult part is ensuring a resolved outcome generates a charge exactly one time, even in the face of worker crashes, message redeliveries or downstream API failures.
Our solution is a multi-stage resolution process. An outcome that meets its billable conditions does not immediately become a charge. It first enters a "resolved" state within our system. It then sits in a configurable settlement window, which can be minutes or days long. During this period, the outcome can still be reversed by subsequent events, such as a user cancellation or a support-initiated credit. Only after this window closes without a reversal is the outcome committed as a permanent, immutable charge.
Our stack is purpose-built for this workflow. While Dragonfly manages the hot, mutable state of an outcome, we use PostgreSQL as the final, transactional source of truth for all settled outcomes and charges. We leverage its ACID guarantees to ensure that the creation of a charge is an atomic, idempotent operation. This two-phase process prevents partial or duplicate charges entirely.
This design avoids a common and critical failure mode. A naive system might call a payment processor's API directly from an event consumer. If the consumer crashes after the API call but before committing its stream offset, it will double-charge upon restart. This dual-write problem is well documented, for example in this walkthrough of the transactional outbox pattern. Our settlement layer and transactional commit process eliminate this entire class of errors.
| Capability | Naive cron job approach | Purpose-built resolution layer |
|---|---|---|
| Correctness | Prone to double-charging and missed events | Guarantees exactly-once effects via settlement |
| Latency | High latency; batch-oriented | Single-digit millisecond event ingestion |
| Scalability | Fails under bursty, high-volume load | Horizontally scalable to millions of outcomes |
| Reversals | No native support; requires complex manual logic | Built-in settlement window for cancellations |
| Auditability | Opaque; difficult to trace charges | Every charge is traceable to source events |
Designing for Reliability and Auditability
The stakes in billing are absolute. Downtime is lost revenue. Data loss is a catastrophic breach of customer trust. We designed our system from the ground up with these realities in mind. We run a full multi-AZ deployment for every component in our stack, from the ingestion APIs to the final transactional database. The system is built to survive a zone failure without data loss or significant service interruption.
Our durability and recovery strategy is anchored by the append-only event log in Redpanda. This log is the ultimate source of truth for every action an agent has ever taken. We continuously archive this log to Amazon S3 for long-term retention and disaster recovery. This architecture allows us to perform a point-in-time recovery, completely rebuilding the state of every outcome from scratch if necessary. All settled charges and contracts are transactionally secured in our multi-AZ PostgreSQL cluster.
Auditability is a first-class design requirement, not an afterthought. A customer will inevitably ask, "Why was I charged for this?". The system must provide a definitive, verifiable answer. Our architecture links every single charge back to its settled outcome and from there to the exact sequence of events that triggered it. There is no ambiguity. We wrote about what that looks like on the invoice itself in How Transparent Invoicing Stops AI Billing Disputes.
We use ClickHouse to power this capability. Its ability to scan billions of events in milliseconds provides the fast query performance needed for the audit trail. This data also powers our simulation engine, which replays historical event streams against new or modified conditions and prices. Teams can accurately forecast the revenue impact of a pricing change before it ever touches a production customer, a process we covered in How to Test Your Outcome Pricing Model Before Launch. Building this replay and audit capability is a massive project in itself, but it is essential for operating a billing system that earns and keeps customer trust.
Infrastructure, Not a Project
Building a correct, scalable and auditable outcome resolution layer is a multi-year infrastructure commitment. It requires three to four senior engineers working for over two quarters just to produce the first correct invoice, plus a permanent operational load for maintenance, on-call and capacity planning.
This production system is what powers witn. Teams get the entire resolution layer as reliable infrastructure. Define the outcome as a condition. Send events as the agent works. The charge settles when the condition holds through the settlement window. Read the docs to see how it works.
More from the blog
witn vs Orb
Compare witn and Orb for AI agent billing. Where usage-based metering fits, where outcome-native billing wins and how to choose for your product.
How to Test Your Outcome Pricing Model Before Launch
De-risk your move to outcome-based billing. This guide shows AI agent builders how to simulate pricing against historical data and forecast revenue.
Metronome Alternatives After the Stripe Acquisition
Stripe acquired Metronome in January 2026. Here are five alternatives for AI billing, from usage metering to outcome-based billing and how to choose.
5 Paid.ai Alternatives for AI Agent Billing in 2026
Comparing Paid.ai with witn, Metronome, Orb, Lago and Nevermined. What each platform does well and how to pick billing infrastructure for your AI agent.
How Voice AI Companies Price Today and Why Per Minute Billing Is a Trap
Explore current voice AI pricing models and understand why per-minute billing hinders innovation. Learn how outcome-based pricing aligns incentives and drives growth.