How to Test Your Outcome Pricing Model Before Launch
De-risk your move to outcome-based billing. This guide shows AI agent builders how to simulate pricing against historical data and forecast revenue.
The Financial Uncertainty of Value-Based Pricing
The idea behind outcome-based pricing for AI agents is simple and powerful. You charge for the value delivered. Instead of billing for inputs like seats or minutes, you invoice for a resolved support ticket, a qualified sales lead or a completed booking. The model aligns your success directly with your customer's success. Yet this is often where finance teams hesitate. We can all picture the meeting where the revenue forecast chart has more question marks than numbers.
A fixed subscription is predictable. Outcome-based invoices are not. That uncertainty is what stalls the transition. How do you build a budget when you do not know what the invoices will look like? The fear is valid. The answer is not to abandon the model. It is to find out what those invoices would look like before committing.
That is what a pricing simulation does. It is not guesswork. It uses the historical data you already have to model the new pricing before a single contract changes. It turns a leap of faith into a calculated business decision.
Backtesting Your Model with Historical Data
The first step is to look at the data you already collect. Most companies building AI agents already track the necessary signals. User actions, API calls, status changes logged in tools like Segment, PostHog or Rudderstack. The data required to model your new pricing is almost certainly there, waiting to be used.
The process is to replay this historical event data through your proposed outcome definition. Think of it like running a film of last quarter's activity through a new lens. Take all support interactions from the last three months and apply a new rule: "charge per ticket that receives a customer satisfaction score of 4 or higher". Suddenly an abstract pricing idea becomes a concrete calculation.
The goal of this first backtest is a tangible, line-by-line invoice showing exactly what each customer would have paid under the new model. That moves the conversation from theoretical benefits to a financial document your team can analyze. It answers the most important question first: based on past activity, what would this change have meant for our revenue and for our customers' costs?
Refining What Counts as Value
The first backtested invoice is only a starting point. The real work is iteration. Change one condition at a time, re-run the simulation and watch how the invoice moves. This is where you decide what counts as value and what does not.
Two examples show how much a single condition matters:
- A booked appointment seems straightforward. Refine it to only count if the appointment is not cancelled within 24 hours. Rerunning the simulation shows precisely how much revenue that one condition protects.
- A resolved support ticket could be any closed ticket. But users open tickets by accident and never reply. A customer-aligned definition requires a genuine two-way exchange and excludes single inbound messages with no follow-up. That keeps every charge tied to real value.
This iterative loop is where you set exclusion criteria and measurement windows that prevent charges for false positives. It is fundamental to customer trust. The SaaS CFO makes the same point in its guide on building an outcome-based pricing plan: the plan stands on clearly defined, measurable outcomes. We covered how to pick that definition in Defining Concrete Billable Outcomes for AI Agents.
Each refinement translates directly into a billable condition. Explicit rules you can test, one leaf at a time:
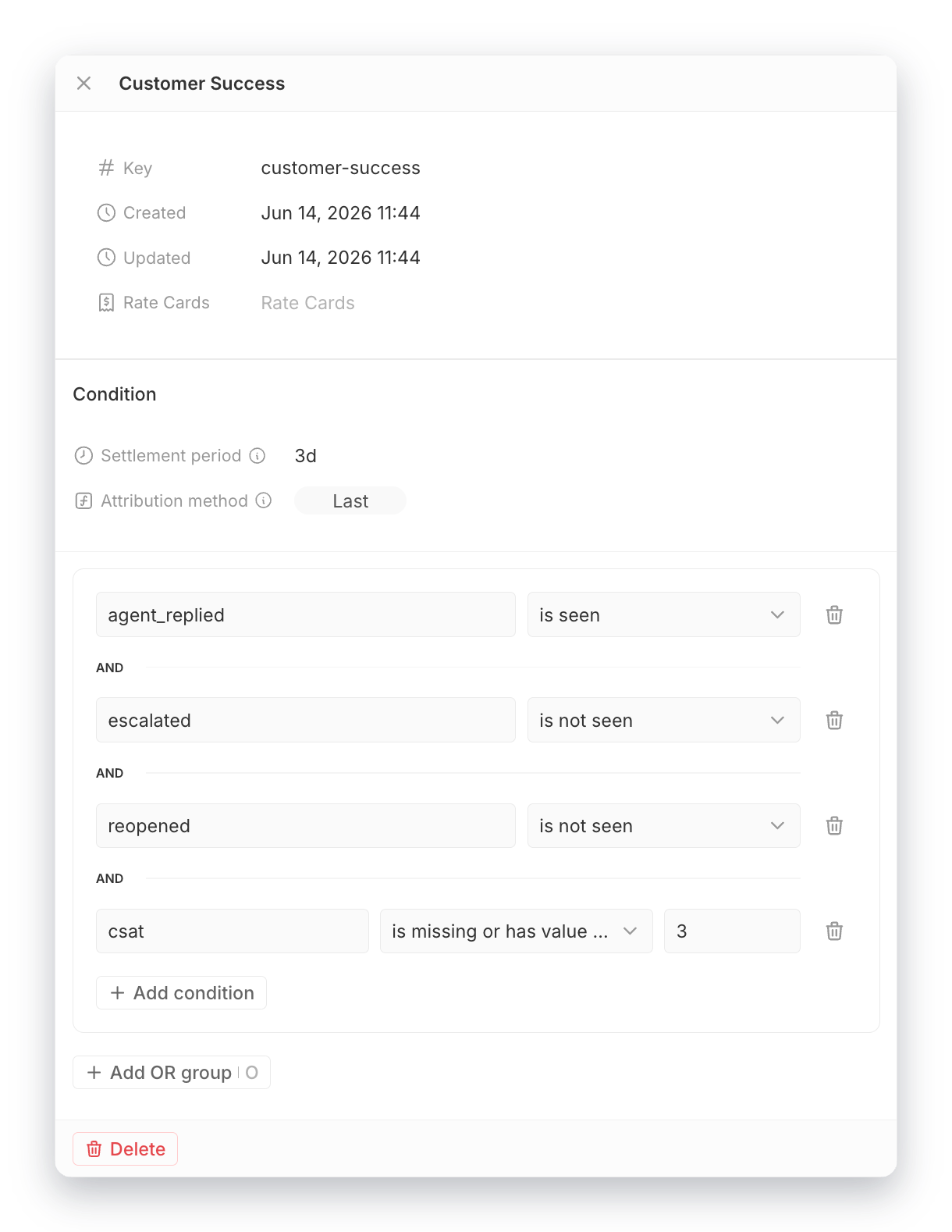
Comparing Financial Impact for Business and Customers
With a refined model, the next step is a direct comparison. The simulation should produce a report that places the new outcome-priced invoice next to the invoice the customer actually paid under the old model. Aggregate these comparisons across your customer base and your finance team sees exactly how total revenue would have shifted last month or last quarter.
Two scenarios will emerge. If the new model produces a higher bill for a customer, the simulation must also show the corresponding increase in value they received. If the model produces a revenue drop for your business, that needs to be identified and planned for long before launch.
| Metric | Current model (per-seat) | Simulated model (outcome-based) | Implication |
|---|---|---|---|
| Customer A invoice | $500 (10 seats) | $620 (310 resolutions) | Customer pays more but received 310 verified outcomes |
| Customer B invoice | $250 (5 seats) | $210 (105 resolutions) | Customer pays less due to lower usage, improving alignment |
| Total monthly revenue | $25,000 | $23,500 | A projected 6% revenue dip to address before launch |
| Effective price per outcome | N/A | $2.00 | A clear, value-based unit cost |
The data here is hypothetical, replayed from a sample customer base with the outcome defined as a resolved support ticket. The shape of the analysis is the point. Assumptions become numbers.
Validating the Model with Trusted Customers
After internal analysis, run the simulation with a small group of trusted customers. This is not a sales meeting. It is a learning session. Present their real historical usage and walk them through the simulated invoice they would have received under the new model.
The goal is to listen. Pay attention to the moments where a customer hesitates, questions a charge or feels the logic is unfair. Does their definition of a "qualified lead" match yours? Is the bill harder to predict than they expected? Every objection raised in this controlled setting is a billing dispute defused before it ever reaches a real invoice.
Trust depends on every charge being explainable and tied to value the customer recognizes. We covered what that looks like on the invoice itself in How Transparent Invoicing Stops AI Billing Disputes. When the numbers are this open, the transition becomes collaborative instead of unilateral.
Future-Proofing Your Pricing Against Product Improvements
Many input-based pricing models contain a hidden flaw: the efficiency trap. Consider a voice AI agent priced per minute. Your team ships an improvement that resolves calls 50% faster and revenue falls precisely because the product got better. You are penalized for innovation. We dug into this failure mode in Why Your AI Product's Success Could Shrink Your Revenue.
Outcome pricing flips the dynamic. Bill per resolved call instead of per minute and revenue is protected. Getting faster improves your margins instead of compressing your revenue. Your simulation should test this directly, not just look backward:
- Establish a baseline. Simulate revenue with your product's current performance.
- Create a future scenario. Model a significant improvement, like your agent becoming twice as efficient at its core task.
- Run the simulation again. Compare revenue and margins under the old input-based model and the new outcome-based model.
Simulation is not just a launch tool. It is how you check that the model stays financially sound as your product improves.
witn is billing infrastructure built for the model you just validated. Define the outcome as a condition. Send events as the agent works. The charge settles when the condition holds through the settlement window. Read the docs to see how it works.
More from the blog
witn vs Orb
Compare witn and Orb for AI agent billing. Where usage-based metering fits, where outcome-native billing wins and how to choose for your product.
Metronome Alternatives After the Stripe Acquisition
Stripe acquired Metronome in January 2026. Here are five alternatives for AI billing, from usage metering to outcome-based billing and how to choose.
5 Paid.ai Alternatives for AI Agent Billing in 2026
Comparing Paid.ai with witn, Metronome, Orb, Lago and Nevermined. What each platform does well and how to pick billing infrastructure for your AI agent.
witn vs Orb
Compare witn and Orb for AI agent billing. Where usage-based metering fits, where outcome-native billing wins and how to choose for your product.
Metronome Alternatives After the Stripe Acquisition
Stripe acquired Metronome in January 2026. Here are five alternatives for AI billing, from usage metering to outcome-based billing and how to choose.